jupyter notebooks
setup
- open “anaconda prompt”
- type and run
conda create -n "datascience" - type and run
conda activate datascience - type and run
conda install pip - type and run
pip install notebook - type and run
jupyter notebook
maak de dir niet startend met een punt :3
pip install pandaspip install numpypip install seaborn
re-launch
- open “anaconda prompt”
- type and run
conda activate datascience - type and run
jupyter notebook
Datasets
kaggle is a website to find datasets, and so is huggingface
Begrippen
Univariate analysis
- Univariate analysis - Notebook 1
je pakt hierbij een row aan data en die ligt je uit
- Categorisch Hierbij kijk ja naar hoevaak een key voorkomt en zet dit in een grafiek, barchart bijv.
- Numeric Hierbij kan je boxplots gebruiken om te kijken naar uitliggers, maar ook kijken naar Gemiddelde, Mediaan, Modus en Berijk
Boxplot
- Boxplot (Box-and-Whisker Plot) – Notebook 1
Een boxplot is een grafiek die helpt om de verdeling van numerieke data snel te begrijpen.
Het laat zien:- Mediaan (middelste waarde)
- Kwartielen (Q1 = 25%, Q3 = 75%)
- Whiskers (lijnen die data binnen bereik tonen, zonder uitbijters)
- Outliers (uitbijters: extreem lage of hoge waarden, getoond als stipjes)

- De box (doos):
Geeft het middenste 50% van de data weer (tussen Q1 en Q3) - De lijn in de box:
Dat is de mediaan (het middelste datapunt) - Whiskers:
Lijnen die gaan van de box naar de kleinste/grootste niet-uitbijtende waarden - Outliers:
Waarden die ver buiten de rest vallen, worden apart weergegeven als stipjes Voorbeeld: Stel je hebt deze data:
[80, 82, 78, 85, 79, 81, 400] - De meeste waardes liggen rond de 80
- Maar 400 ligt er ver buiten → dat is een outlier
Distributies
- Distributies - Notebook 2
Een distributie is een manier om te kijken hoevaak dingen voorkomen in verband tot elkaar. De meer data er is, de smoother de analysis grafiek.
- Uniform distributie Dit is wat je krijgt als je ongeveer een rechte lijn hebt, als je met 1 dobbelsteen vaak genoeg gooit zal elk nummer ongv net zo vaak gegooid worden.
- Normaal distributie dit is curve die je krijgt als je bijcoorbeeld met 2 dobbelstenen gooit. de 2 en 12 is weinig gegooid vergeleken de 7. example picture irl examples of this
- Er zijn er nog meer, die kan je hier vinden.
{kind=link}
Centrale Limietstelling
- Central Limit Theorem (Centrale Limietstelling) - Notebook 2
Als je veel willekeurige steekproeven neemt van een bepaalde grootte uit elke populatie (maakt niet uit hoe die verdeeld is), en je berekent het gemiddelde van elke steekproef, dan geldt het volgende:
- De verdeling van die steekproefgemiddelden wordt ongeveer normaal verdeeld (belvormig)
- Het gemiddelde van die steekproefgemiddelden is gelijk aan het populatiegemiddelde
- De spreiding (standaardafwijking) van die gemiddelden wordt kleiner naarmate de steekproeven groter zijn
- Dit geldt ook als de oorspronkelijke data niet normaal verdeeld is!
Waarom is dit handig?
Omdat je dan: - Hulpmiddelen van de normale verdeling kunt gebruiken (zoals betrouwbaarheidsintervallen) ook bij niet-normale data
- Voorspellingen en uitspraken kunt doen over gemiddelden van de populatie
- Kunt verklaren waarom het steekproefgemiddelde bij grote steekproeven betrouwbaar is
Betrouwbaarheidsinterval
- Confidence Interval (Betrouwbaarheidsinterval) – Notebook 2
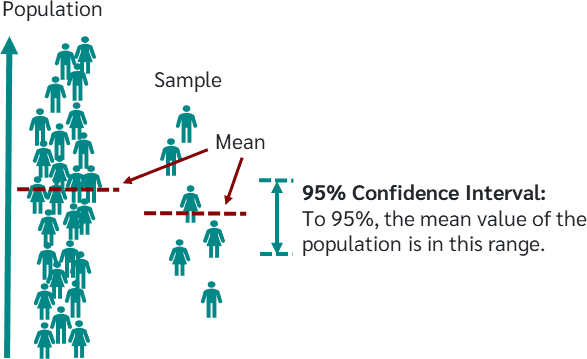
Een betrouwbaarheidsinterval is een bereik van waarden waarvan we denken dat het met een bepaalde zekerheid de echte populatiewaarde bevat (zoals het gemiddelde of een proportie), gebaseerd op een steekproef.- Meestal gaat het over het gemiddelde, dus daar focussen we op.
- Een 95% betrouwbaarheidsinterval zegt: “We zijn 95% zeker dat het echte populatiegemiddelde binnen dit interval ligt.”
- Hoe hoger de zekerheid (bijv. 99% in plaats van 95%), hoe groter het interval wordt.
- Bij 100% zekerheid krijg je een interval van -∞ tot +∞, wat nutteloos is.
- Daarom is in de wetenschap 95% betrouwbaarheid standaard afgesproken.
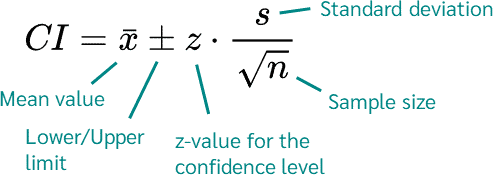
Bivariate analyse
-
Bivariate analyse – Notebook 3
Hierbij kijk je naar de relatie tussen twee variabelen (twee kolommen).Afhankelijk van het type van beide variabelen kies je de juiste techniek:
- Numeriek VS Numeriek
- Numeriek VS Categoraal
- Categoraal VS Categoraal
Numeriek VS Numeriek
- Voorbeelden
- Lichaamslengte VS Schoenmaat
- Leeftijd VS Tijd om 1 km te lopen
- Lands‑werkloosheidspercentage VS Geluksindex
- Omzet per klant VS Klantlevensduur
- Aantal wenslijst‑toevoegingen VS Aantal aankopen
- Cijfer student VS Aanwezigheidspercentage
Scatterplot
-
Scatterplot (Puntenwolk) – Notebook 3
Een scatterplot toont de relatie tussen twee numerieke variabelen.- X‑as: waarden van variabele 1 (bijv. sepal_length)
- Y‑as: waarden van variabele 2 (bijv. petal_length)
- Punt: één waarneming (één bloem in de Iris‑dataset)
Waarvoor handig?
- Correlaties of lineaire relaties spotten
- Clusters of groepen herkennen
- Uitbijters zien
Pearson‑correlatie
-
Pearson‑correlatie – Notebook 3
Een maat voor de lineaire relatie tussen twee numerieke variabelen. Geeft een waarde tussen −1 en +1:- −1: perfecte negatieve lineaire relatie
- ** 0**: geen lineaire relatie
- +1: perfecte positieve lineaire relatie
Interpretatie
- Dicht bij ±1 → sterke lineaire samenhang
- Dicht bij 0 → zwakke of geen lineaire samenhang
Numeriek VS Categoraal
- Numeriek VS Categoraal – Notebook 3 Hier vergelijken we een numerieke variabele met een categorische variabele.
Voorbeelden
- Maandelijks inkomen VS Hoogst behaald diploma
- Lichaamslengte VS Land van herkomst
- Gelukswaardering VS Land van herkomst
- Omzet VS Accountmanager
- Omzet VS Productcategorie
- Omzet VS Game‑genre
- Retentie (%) VS Software‑versie
Gemiddelden per categorie
In univariate analyse gebruikten we betrouwbaarheidsintervallen voor numerieke data.
Bij numeriek VS categoraal kunnen we per categorie het gemiddelde berekenen én een betrouwbaarheidsinterval tonen om te zien of categorieën echt van elkaar verschillen.
Categoraal VS Categoraal
- Categoraal VS Categoraal – Notebook 3
Hier onderzoeken we de relatie tussen twee categorische variabelen.
Voorbeelden
- Inbound‑kanaal VS Type klant
- Opleidingsniveau VS Functie
- Regio burger VS Stemgedrag
- Shirtkleur crew‑lid in Star Trek VS Overleving crew‑lid
- Nieuwsbrief‑inschrijving (Ja/Nee) VS Churn (Ja/Nee)
- Eiland van pinguïn VS Pinguïn‑soort
Contingentietabel (crosstab)
-
Een contingentietabel toont hoe vaak elke combinatie van categorieën voorkomt.
-
Rijen = waarden van variabele A, kolommen = waarden van variabele B, cellen = tellingen.
Type A1 Type A2 Type A3 Categorie B1 12 5 8 Categorie B2 4 15 2 Categorie B3 7 3 10
stack() en unstack() in pandas
- unstack(level)
Kantelt een indexniveau (MultiIndex‑rij) naar kolommen → bredere DataFrame. - stack(level)
Kantelt een kolomniveau naar rijen → diepere MultiIndex op de rij‑as.
Gebruik unstack om een crosstab overzichtelijker als DataFrame te tonen; gebruik stack om weer terug te gaan naar lange vorm.
Chi‑kwadraat‑toets van onafhankelijkheid
-
chi2_contingency– scipy.stats
Test of twee categorische variabelen onafhankelijk zijn.- Chi‑kwadraat‑statistiek: maat voor verschil tussen waargenomen en verwachte frequenties (onder aanname van onafhankelijkheid).
- p‑waarde: kans dat zo’n groot verschil toevallig ontstaat.
- p < 0.05 → verwerp H₀ (onafhankelijkheid), er is een significante associatie.
- Verwachte frequenties: cellentellingen bij geen relatie.
Interpretatie
- Grote χ² en zeer kleine p‑waarde → cellentellingen wijken significant af van onafhankelijkheids‑verwachting.
- Conclusie: de twee categorische variabelen hangen samen (niet door toeval).
In gewone taal
- Je maakt een tabel van kruistellingen (contingentietabel).
- Je voert de chi‑kwadraat‑toets uit op die tabel.
- Een p‑waarde < 0.05 betekent: “Er is meer verschil dan je door toeval zou verwachten.”
- Dus: categorieën zijn niet onafhankelijk, er is een verband.
Seaborn barplot
-
seaborn.barplot()– Notebook 3 Maakt een staafdiagram waarin per categorie:- De staafhoogte het gemiddelde is van de numerieke waarden
- De foutbalk (error bar) standaard een 95% betrouwbaarheidsinterval toont
Voordelen t.o.v. een simpele barplot
- Automatisch berekenen van gemiddelden bij meerdere datapunten per categorie
- Tonen van betrouwbaarheidsintervallen
Wat is NumPy?
-
NumPy (Numerical Python) – Notebook 3
Krachtige Python‑bibliotheek voor numerieke berekeningen.- ndarray: multi‑dimensionale array
- Rekenkundige bewerkingen: som, gemiddelde, dot‑product, enz.
- Lineaire algebra, random‑nummers, Fourier‑transformaties, …
Waarom gebruiken?
- Zeer snel op grote arrays
- Basis voor veel andere libraries (pandas, scikit‑learn, etc.)
- Handige functies voor statistiek en wiskunde