202511131122
Status: idea
Tags: Datascience, Machine Learning
K-Means clustering
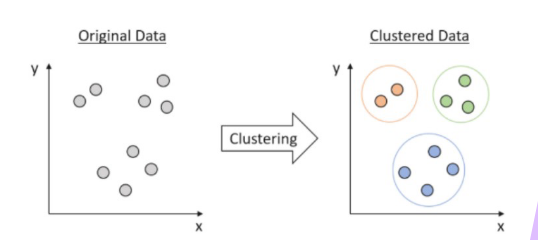
K-Means clustering is een unsupervised learning methode. Het doel is om dignen die dichtbij elkaar liggen te gorperen in k clusters. Elke cluster heeft een centroid, dit is de center van de cluster. Punten die in een cluster zitten lijken op elkaar, punten in een andere cluster zijn anders.
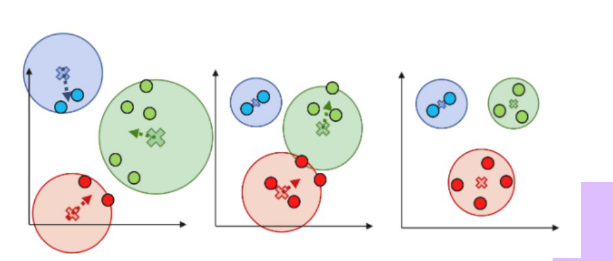
Stappen van K-Means
- Als eerste kies je een
knummer, dit is het aantal clusters. - Plaats de
kcentroids op een random plek. - elk data punt kiest de centroid die het dichtste bij ligt.
- herbereken waar de centroid ligt gebaseerd op de average van de afstand tussen de centroid en de data punten.
- herhaal dit tot de centroids niet echt veel meer bewegen.
Het doel van K-Means is om de cluster zo dicht mogelijk bij de centroid te krijgen. Er is hier een gekke wiskundige calculation voor:
- is the objective function (or cost function, often called the Within-Cluster Sum of Squares, or WCSS). The goal of K-means is to minimize this value.
- is the outer summation, summing over all clusters.
- is the inner summation, summing over all data points that belong to the -th cluster, .
- is the squared Euclidean distance between a data point and the mean (centroid) of the cluster it belongs to.
De output van een K-Means heeft labels, maar dit zijn cluster labels (0, 1, 2…) en geen class namen.
Gebruiken van K-Means
- Customer segmentation: je kan vergelijkbare klanten groeperen
- Image comrpession: cluster simular colors
- Document clustering: groeperen van vergelijkbare text.
- Andere taken waar patronen vinden nuttig is.
References
Dit is iets wat we leren voor Datascience. dit was informatie vanuit avans 2-1 datascience 2025-11-10. en daarbij horen deze slides